






引言
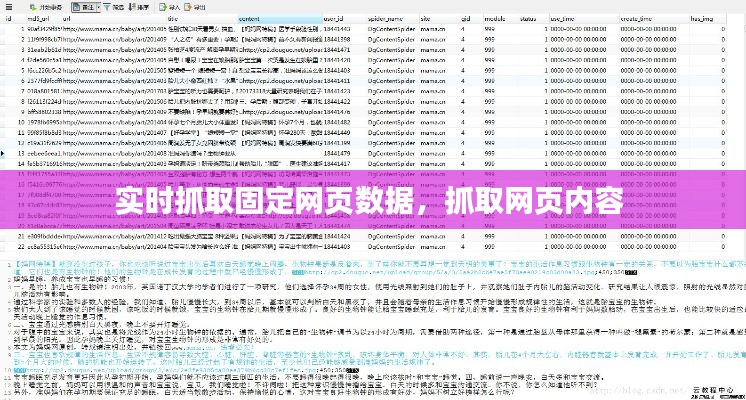
在互联网时代,数据已成为企业、研究机构和政府部门的重要资产。实时抓取固定网页数据对于监控市场动态、分析竞争对手、收集情报等方面具有重要意义。本文将探讨实时抓取固定网页数据的方法、工具及其应用场景。
什么是实时抓取固定网页数据
实时抓取固定网页数据指的是定期从特定的网页上获取数据,并实时更新到数据库或分析系统中。这种数据抓取方式可以保证数据的时效性和准确性,对于需要实时监控信息的企业或机构来说尤为重要。
实时抓取固定网页数据的方法
实时抓取固定网页数据的方法主要有以下几种:
使用爬虫(Crawler)技术:爬虫是一种自动化的网络爬取工具,可以按照预设的规则从网页上抓取数据。常见的爬虫有Python的Scrapy、Java的Nutch等。
使用API接口:许多网站都提供了API接口,可以直接调用获取数据。这种方式通常需要注册账号并获取API密钥。
使用第三方数据服务:一些第三方数据服务平台提供了固定网页数据的抓取服务,用户只需付费即可获取所需数据。
实时抓取固定网页数据的工具
以下是几种常用的实时抓取固定网页数据的工具:
Scrapy:Python的一个快速、高层的网页抓取和爬取框架,适合大规模的数据抓取任务。
BeautifulSoup:Python的一个库,用于解析HTML和XML文档,可以方便地从网页中提取数据。
Requests:Python的一个库,用于发送HTTP请求,可以用来获取网页内容。
PyQuery:Python的一个库,提供了一种简单的方式来解析和操作HTML和XML文档。
实时抓取固定网页数据的应用场景
实时抓取固定网页数据在以下场景中具有重要作用:
市场监控:企业可以通过实时抓取竞争对手的网页数据,了解其产品、价格、促销等信息,以便及时调整自己的市场策略。
舆情分析:政府部门或企业可以通过实时抓取社交媒体、新闻网站等平台的数据,了解公众对某一事件或产品的看法,为决策提供参考。
数据挖掘:研究人员可以通过实时抓取大量网页数据,进行数据挖掘和分析,发现潜在规律和趋势。
自动化测试:开发人员可以通过实时抓取网页数据,进行自动化测试,确保网站或应用程序的正常运行。
注意事项
在实时抓取固定网页数据时,需要注意以下几点:
遵守网站robots.txt规则:在抓取数据前,应先查看目标网站的robots.txt文件,了解其允许或禁止抓取的页面。
合理设置爬虫参数:合理设置爬虫的抓取频率、并发数等参数,避免对目标网站造成过大压力。
尊重版权和隐私:在抓取数据时,应尊重网站的版权和用户的隐私,不得用于非法用途。
结论
实时抓取固定网页数据是现代数据获取的重要手段,对于企业、研究机构和政府部门来说具有重要意义。通过合理选择方法、工具,并注意相关事项,可以有效地获取实时数据,为决策提供有力支持。
转载请注明来自专业的汽车服务平台,本文标题:《实时抓取固定网页数据,抓取网页内容 》




 琼ICP备2024026137号-1
琼ICP备2024026137号-1